
The impossibility of solving the problem of numbers, and the two ways of writing them
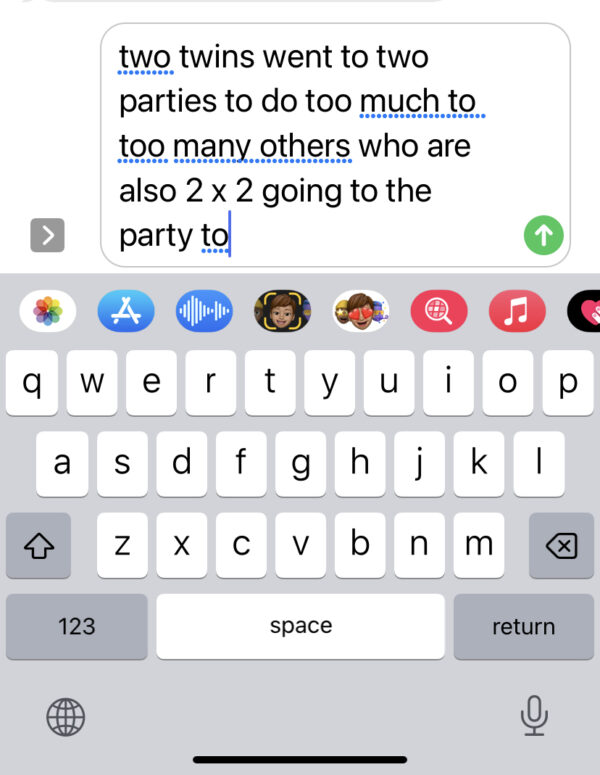
Confusing dictated text for applications like Siri and other voice assistants arises from the inherent complexities of language, context, and homophones. The examples of “4,” “four,” “fore,” and “for,” as well as “two,” “2,” “too,” and “to,” highlight the challenges and demonstrate the near-impossibility of completely solving this issue for dictation to speech. Particularly challenging are words and ciphers like “four” and “4,” as well as “five” and “5,” where the same meaning is conveyed using different formats.

1. Homophones and Context: Dictated text often lacks visual and gestural cues present in written communication. This absence of cues makes distinguishing between homophones difficult. For instance, when dictating “4,” the listener can’t distinguish whether it’s “four,” “fore,” or “for” without clear context.

2. Contextual Ambiguity: In the sentence “Four golfers shouted ‘fore’ 4 times,” AI must determine whether “4” should be transcribed as a number or as “fore.” Without broader context, the system is challenged to decide the intended meaning accurately.
3. Nuances in Inflection: Voice inflection, pauses, and tone contribute to comprehension in spoken language. However, voice assistants might struggle to capture these nuances, leading to misinterpretation of homophonic words.
4. Homophones with Numerical Values: Transcribing “four” as “4” can create ambiguity, especially in contexts like “They shouted ‘fore’ for four times.” Both “four” and “4” could be valid interpretations.
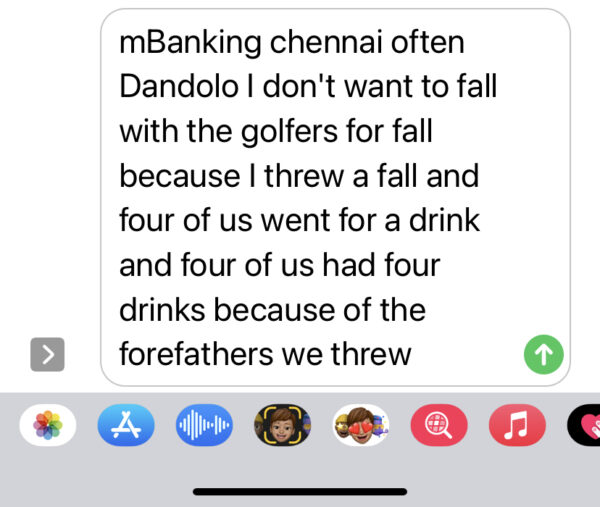
mBanking gobbledygook by Siri with which I dictated this description as well that’s why it’s also gobbledygook boo
5. Synonyms and Ambiguity: The word “to” can be a preposition or part of an infinitive verb, adding complexity. In “They went to the store,” “to” is a preposition, whereas in “They wanted to go,” “to” is part of an infinitive verb.

Corporate Idiot
6. Ambiguous Numbers: Transcribing numbers like “4” using words like “four” adds an extra layer of complexity. “Four” can also refer to a count, creating uncertainty in interpretation.
7. Variability in Speech: Accents, dialects, and speech patterns vary widely. A word pronounced slightly differently might lead to an incorrect transcription.

Solving these challenges is intricate because the fundamental issue lies in the limitations of speech recognition systems. While AI can use context analysis, probabilistic reasoning, and linguistic rules, achieving perfect accuracy in dictation remains elusive due to the multifaceted nature of human language and the limitations of current technology. Improvements will continue, but complete resolution for this complex problem may remain a very distant goal.

what’s inside your head? words? Ideas? Whichever, Siri is not going to express it for you
so I don’t think anytime in the future you’ll be telling your spaceship with natural language dictation to plot a course to alpha Centauri, because it might be just potting a fleur de lys to Alf!

Smiley Tim the 2/two/too faced Corporate Fake Dude I would be ashamed of if he was my father
No we are nowhere near guardians of the Galaxy yet!